企业数据 + AI
企业基础信息
司法诉讼记录
企业风险
知识产权
股东结构
企业基础信息
司法诉讼记录
企业风险
知识产权
股东结构
企业基础信息
司法诉讼记录
企业风险
知识产权
股东结构
企业基础信息
司法诉讼记录
企业风险
知识产权
股东结构
荣誉资质
企业统计云图
股票债券
年报数据
荣誉资质
企业统计云图
股票债券
年报数据
荣誉资质
企业统计云图
股票债券
年报数据
荣誉资质
企业统计云图
股票债券
年报数据
数据优势
提供全维度指标,帮助了解企业的各个方面
每日更新
全行业企业数据接口每日同步最新工商/经营数据








无缝集成
即插即用,适用于任何AI 模型和工具
更深入的数据洞察
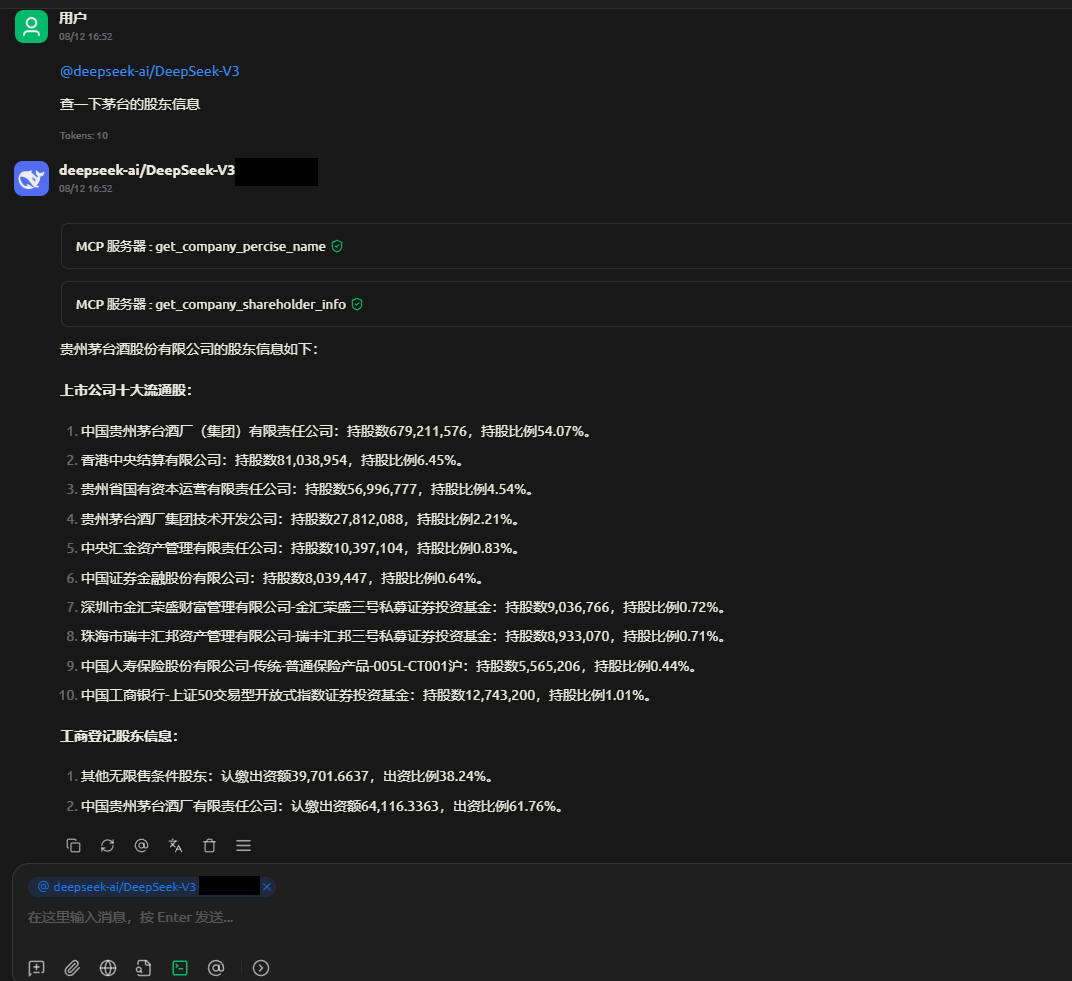
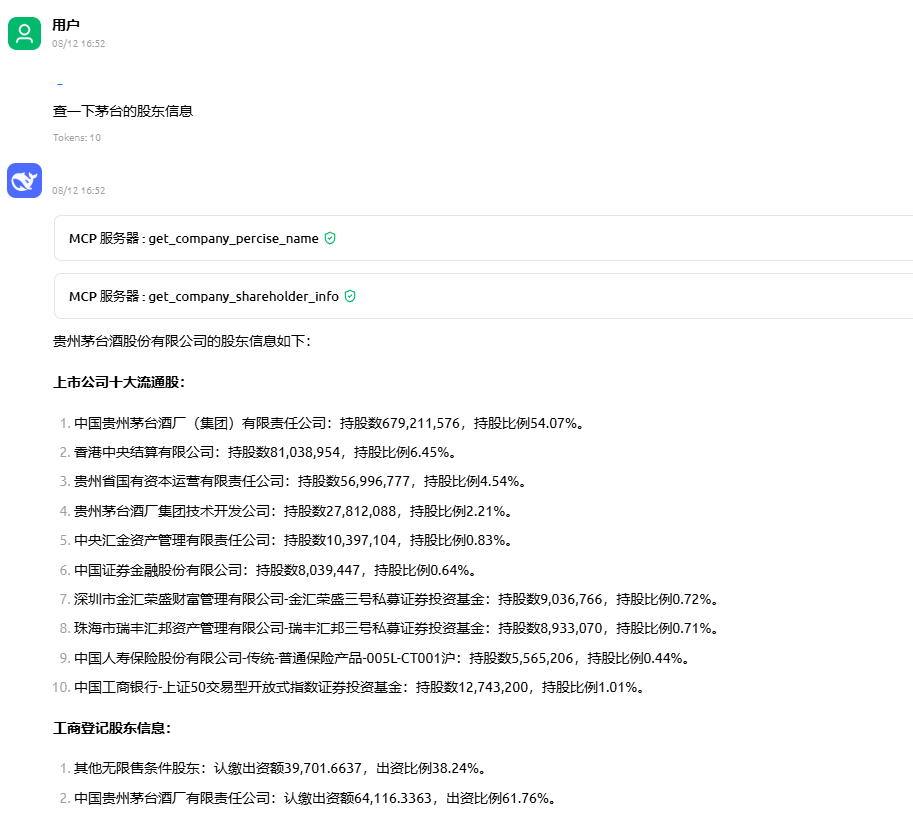
招商/风控/尽调?告别数据收集难!像投资人一样看透企业底细
价格实惠
公测阶段免费使用
index.py
import requests
from bs4 import BeautifulSoup
import pandas as pd
def fetch_session_cookies():
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
}
url = "https://www.xxx.com"
res = requests.get(url=url, headers=headers)
return res.cookies
def scrape_detailed_info(entity_id, current_cookies):
url = "https://www.xxx.com/cbase/" + entity_id
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
}
res = requests.get(url, headers=headers, cookies=current_cookies)
soup = BeautifulSoup(res.text, 'lxml')
table = soup.find_all('table')[0]
df = pd.read_html(str(table))[0]
return df
def retrieve_company_data(firm_name):
firm_name = firm_name.replace("(", "(").replace(")", ")")
session_cookies = fetch_session_cookies()
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
}
url = "https://www.xxx.com/web/search"
params = {
"key": firm_name,
}
res = requests.get(url=url, params=params, headers=headers, cookies=session_cookies)
soup = BeautifulSoup(res.text, 'lxml')
main_info_div = soup.find_all(attrs={"class": "maininfo"})
if main_info_div:
link_element = main_info_div[0].find_all("a")[0]
scraped_name = "".join(em.text for em in link_element.find_all("em"))
if scraped_name == firm_name:
profile_link = link_element.attrs.get('href')
res = requests.get(url=profile_link, headers=headers, timeout=60)
soup = BeautifulSoup(res.text, 'lxml')
table = soup.find_all('table')[0]
df = pd.read_html(str(table))[0]
if len(df) < 5:
entity_id = profile_link.strip(".html").split("/")[-1]
return scrape_detailed_info(entity_id, session_cookies)
return df
index.py
from fastmcp import Client
client = Client(config)
async with client:
enterprise = await client.call_tool(
"""通过 MCP 工具调用获取公司的工商信息。"""
"get_company_basic_info",
{
"company_name": "阿里巴巴(中国)有限公司"
})
MCP / API 多种方式调用
告别爬虫,10 倍简化你的代码

产品理念
成立十余年来,我们不仅将数据视为资源,更是洞见未来的钥匙。
我们始终坚持以客户业务场景为导向,通过“数据+算法+行业know-how”的三维融合,帮助合作伙伴构建数据驱动的智能决策体系,实现从数据资源到商业价值的高效转化。
- 全量企业数据
- 1亿+
- 字段覆盖企业五大主题
(主体/经营/资产/风险/关联) - 1800+
- 企业关系网络
- 7亿+
- 企业定位准确率高达90%
使用不同的市场产品热词、头部国央企简称、各国标行业代表企业/产品名字查询企业测试结果 - 90%+
近百家金融机构、知名企业严选

























联系我们
我们将在7个工作日内回复您
开发者社群
欢迎交流
添加客服微信PrimeMatrix 进群
进群